diff --git a/.changelogs/1.0.0/3_create_grouping_include_feature.yml b/.changelogs/1.0.0/3_create_grouping_include_feature.yml
new file mode 100644
index 0000000..a98a347
--- /dev/null
+++ b/.changelogs/1.0.0/3_create_grouping_include_feature.yml
@@ -0,0 +1,2 @@
+added:
+ - Add include grouping feature to rebalance VMs bundled to new nodes. [#3]
diff --git a/.changelogs/1.0.0/4_create_grouping_exclude_feature.yml b/.changelogs/1.0.0/4_create_grouping_exclude_feature.yml
new file mode 100644
index 0000000..9d88789
--- /dev/null
+++ b/.changelogs/1.0.0/4_create_grouping_exclude_feature.yml
@@ -0,0 +1,2 @@
+added:
+ - Add exclude grouping feature to rebalance VMs from being located together to new nodes. [#4]
diff --git a/.changelogs/1.0.0/7_ignore_vm_by_tag_proxlb_ignore_vm.yml b/.changelogs/1.0.0/7_ignore_vm_by_tag_proxlb_ignore_vm.yml
new file mode 100644
index 0000000..ef8afc2
--- /dev/null
+++ b/.changelogs/1.0.0/7_ignore_vm_by_tag_proxlb_ignore_vm.yml
@@ -0,0 +1,2 @@
+added:
+ - Add feature to prevent VMs from being relocated by defining the 'plb_ignore_vm' tag. [#7]
diff --git a/.changelogs/1.0.0/7_ignore_vms_by_wildcard.yml b/.changelogs/1.0.0/7_ignore_vms_by_wildcard.yml
new file mode 100644
index 0000000..323637b
--- /dev/null
+++ b/.changelogs/1.0.0/7_ignore_vms_by_wildcard.yml
@@ -0,0 +1,2 @@
+added:
+ - Add feature to prevent VMs from being relocated by defining a wildcard pattern. [#7]
diff --git a/.changelogs/1.0.0/release_meta.yml b/.changelogs/1.0.0/release_meta.yml
new file mode 100644
index 0000000..c19765d
--- /dev/null
+++ b/.changelogs/1.0.0/release_meta.yml
@@ -0,0 +1 @@
+date: TBD
diff --git a/README.md b/README.md
index b430f57..bcb47bd 100644
--- a/README.md
+++ b/README.md
@@ -72,8 +72,8 @@ The following options can be set in the `proxlb.conf` file:
| api_pass | FooBar | Password for the API. |
| verify_ssl | 1 | Validate SSL certificates (1) or ignore (0). (default: 1) |
| method | memory | Defines the balancing method (default: memory) where you can use `memory`, `disk` or `cpu`. |
-| ignore_nodes | dummynode01,dummynode02 | Defines a comma separated list of nodes to exclude. |
-| ignore_vms | testvm01,testvm02 | Defines a comma separated list of VMs to exclude. |
+| ignore_nodes | dummynode01,dummynode02,test* | Defines a comma separated list of nodes to exclude. |
+| ignore_vms | testvm01,testvm02 | Defines a comma separated list of VMs to exclude. (`*` as suffix wildcard or tags are also supported) |
| daemon | 1 | Run as a daemon (1) or one-shot (0). (default: 1) |
| schedule | 24 | Hours to rebalance in hours. (default: 24) |
@@ -99,6 +99,17 @@ The following options and parameters are currently supported:
|------|:------:|------:|------:|
| -c | --config | Path to a config file. | /etc/proxlb/proxlb.conf (default) |
+
+### Grouping
+#### Include (Stay Together)
+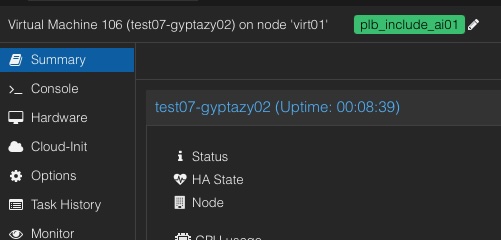 Access the Proxmox Web UI by opening your web browser and navigating to your Proxmox VE web interface, then log in with your credentials. Navigate to the VM you want to tag by selecting it from the left-hand navigation panel. Click on the "Options" tab to view the VM's options, then select "Edit" or "Add" (depending on whether you are editing an existing tag or adding a new one). In the tag field, enter plb_include_ followed by your unique identifier, for example, plb_include_group1. Save the changes to apply the tag to the VM. Repeat these steps for each VM that should be included in the group.
+
+#### Exclude (Stay Separate)
+
Access the Proxmox Web UI by opening your web browser and navigating to your Proxmox VE web interface, then log in with your credentials. Navigate to the VM you want to tag by selecting it from the left-hand navigation panel. Click on the "Options" tab to view the VM's options, then select "Edit" or "Add" (depending on whether you are editing an existing tag or adding a new one). In the tag field, enter plb_include_ followed by your unique identifier, for example, plb_include_group1. Save the changes to apply the tag to the VM. Repeat these steps for each VM that should be included in the group.
+
+#### Exclude (Stay Separate)
+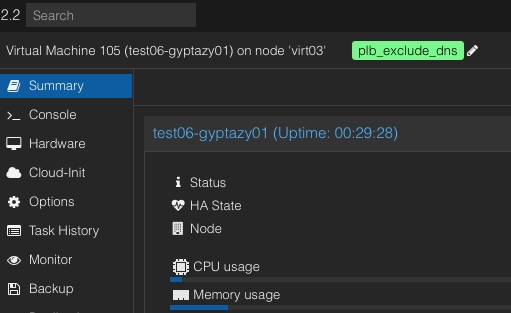 Access the Proxmox Web UI by opening your web browser and navigating to your Proxmox VE web interface, then log in with your credentials. Navigate to the VM you want to tag by selecting it from the left-hand navigation panel. Click on the "Options" tab to view the VM's options, then select "Edit" or "Add" (depending on whether you are editing an existing tag or adding a new one). In the tag field, enter plb_exclude_ followed by your unique identifier, for example, plb_exclude_critical. Save the changes to apply the tag to the VM. Repeat these steps for each VM that should be excluded from being on the same node.
+
+#### Ignore VMs (tag style)
+
Access the Proxmox Web UI by opening your web browser and navigating to your Proxmox VE web interface, then log in with your credentials. Navigate to the VM you want to tag by selecting it from the left-hand navigation panel. Click on the "Options" tab to view the VM's options, then select "Edit" or "Add" (depending on whether you are editing an existing tag or adding a new one). In the tag field, enter plb_exclude_ followed by your unique identifier, for example, plb_exclude_critical. Save the changes to apply the tag to the VM. Repeat these steps for each VM that should be excluded from being on the same node.
+
+#### Ignore VMs (tag style)
+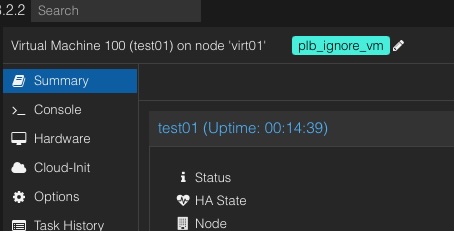 In Proxmox, you can ensure that certain VMs are ignored during the rebalancing process by setting a specific tag within the Proxmox Web UI, rather than solely relying on configurations in the ProxLB config file. This can be achieved by adding the tag 'plb_ignore_vm' to the VM. Once this tag is applied, the VM will be excluded from any further rebalancing operations, simplifying the management process.
+
### Systemd
When installing a Linux distribution (such as .deb or .rpm) file, this will be shipped with a systemd unit file. The default configuration file will be sourced from `/etc/proxlb/proxlb.conf`.
diff --git a/docs/02_Configuration.md b/docs/02_Configuration.md
index e69de29..47374b0 100644
--- a/docs/02_Configuration.md
+++ b/docs/02_Configuration.md
@@ -0,0 +1,10 @@
+# Configuration
+## Grouping
+### Include (Stay Together)
+ Access the Proxmox Web UI by opening your web browser and navigating to your Proxmox VE web interface, then log in with your credentials. Navigate to the VM you want to tag by selecting it from the left-hand navigation panel. Click on the "Options" tab to view the VM's options, then select "Edit" or "Add" (depending on whether you are editing an existing tag or adding a new one). In the tag field, enter plb_include_ followed by your unique identifier, for example, plb_include_group1. Save the changes to apply the tag to the VM. Repeat these steps for each VM that should be included in the group.
+
+### Exclude (Stay Separate)
+ Access the Proxmox Web UI by opening your web browser and navigating to your Proxmox VE web interface, then log in with your credentials. Navigate to the VM you want to tag by selecting it from the left-hand navigation panel. Click on the "Options" tab to view the VM's options, then select "Edit" or "Add" (depending on whether you are editing an existing tag or adding a new one). In the tag field, enter plb_exclude_ followed by your unique identifier, for example, plb_exclude_critical. Save the changes to apply the tag to the VM. Repeat these steps for each VM that should be excluded from being on the same node.
+
+### Ignore VMs (tag style)
+ In Proxmox, you can ensure that certain VMs are ignored during the rebalancing process by setting a specific tag within the Proxmox Web UI, rather than solely relying on configurations in the ProxLB config file. This can be achieved by adding the tag 'plb_ignore_vm' to the VM. Once this tag is applied, the VM will be excluded from any further rebalancing operations, simplifying the management process.
\ No newline at end of file
diff --git a/proxlb b/proxlb
index 236dba6..3509e76 100755
--- a/proxlb
+++ b/proxlb
@@ -29,6 +29,8 @@ try:
_imports = True
except ImportError as error:
_imports = False
+import random
+import re
import requests
import sys
import time
@@ -226,15 +228,18 @@ def get_node_statistics(api_object, ignore_nodes):
for node in api_object.nodes.get():
if node['status'] == 'online' and node['node'] not in ignore_nodes_list:
node_statistics[node['node']] = {}
- node_statistics[node['node']]['cpu_total'] = node['maxcpu']
- node_statistics[node['node']]['cpu_used'] = node['cpu']
- node_statistics[node['node']]['cpu_free'] = int(node['maxcpu']) - int(node['cpu'])
- node_statistics[node['node']]['memory_total'] = node['maxmem']
- node_statistics[node['node']]['memory_used'] = node['mem']
- node_statistics[node['node']]['memory_free'] = int(node['maxmem']) - int(node['mem'])
- node_statistics[node['node']]['disk_total'] = node['maxdisk']
- node_statistics[node['node']]['disk_used'] = node['disk']
- node_statistics[node['node']]['disk_free'] = int(node['maxdisk']) - int(node['disk'])
+ node_statistics[node['node']]['cpu_total'] = node['maxcpu']
+ node_statistics[node['node']]['cpu_used'] = node['cpu']
+ node_statistics[node['node']]['cpu_free'] = int(node['maxcpu']) - int(node['cpu'])
+ node_statistics[node['node']]['cpu_free_percent'] = int((node_statistics[node['node']]['cpu_free']) / int(node['maxcpu']) * 100)
+ node_statistics[node['node']]['memory_total'] = node['maxmem']
+ node_statistics[node['node']]['memory_used'] = node['mem']
+ node_statistics[node['node']]['memory_free'] = int(node['maxmem']) - int(node['mem'])
+ node_statistics[node['node']]['memory_free_percent'] = int((node_statistics[node['node']]['memory_free']) / int(node['maxmem']) * 100)
+ node_statistics[node['node']]['disk_total'] = node['maxdisk']
+ node_statistics[node['node']]['disk_used'] = node['disk']
+ node_statistics[node['node']]['disk_free'] = int(node['maxdisk']) - int(node['disk'])
+ node_statistics[node['node']]['disk_free_percent'] = int((node_statistics[node['node']]['disk_free']) / int(node['maxdisk']) * 100)
logging.info(f'{info_prefix} Added node {node["node"]}.')
logging.info(f'{info_prefix} Created node statistics.')
@@ -243,15 +248,38 @@ def get_node_statistics(api_object, ignore_nodes):
def get_vm_statistics(api_object, ignore_vms):
""" Get statistics of cpu, memory and disk for each vm in the cluster. """
- info_prefix = 'Info: [vm-statistics]:'
- vm_statistics = {}
- ignore_vms_list = ignore_vms.split(',')
+ info_prefix = 'Info: [vm-statistics]:'
+ vm_statistics = {}
+ ignore_vms_list = ignore_vms.split(',')
+ group_include = None
+ group_exclude = None
+ vm_ignore = None
+ vm_ignore_wildcard = False
+
+ # Wildcard support: Initially validate if we need to honour
+ # any wildcards within the vm_ignore list.
+ vm_ignore_wildcard = __validate_ignore_vm_wildcard(ignore_vms)
for node in api_object.nodes.get():
for vm in api_object.nodes(node['node']).qemu.get():
- if vm['status'] == 'running' and vm['name'] not in ignore_vms_list:
+ # Get the VM tags from API.
+ vm_tags = __get_vm_tags(api_object, node, vm['vmid'])
+ if vm_tags is not None:
+ group_include, group_exclude, vm_ignore = __get_proxlb_groups(vm_tags)
+
+ # Get wildcard match for VMs to ignore if a wildcard pattern was
+ # previously found. Wildcards may slow down the task when using
+ # many patterns in the ignore list. Therefore, run this only if
+ # a wildcard pattern was found. We also do not need to validate
+ # this if the VM is already being ignored by a defined tag.
+ if vm_ignore_wildcard and not vm_ignore:
+ vm_ignore = __check_vm_name_wildcard_pattern(vm['name'], ignore_vms_list)
+
+ if vm['status'] == 'running' and vm['name'] not in ignore_vms_list and not vm_ignore:
vm_statistics[vm['name']] = {}
+ vm_statistics[vm['name']]['group_include'] = group_include
+ vm_statistics[vm['name']]['group_exclude'] = group_exclude
vm_statistics[vm['name']]['cpu_total'] = vm['cpus']
vm_statistics[vm['name']]['cpu_used'] = vm['cpu']
vm_statistics[vm['name']]['memory_total'] = vm['maxmem']
@@ -270,74 +298,83 @@ def get_vm_statistics(api_object, ignore_vms):
return vm_statistics
+def __validate_ignore_vm_wildcard(ignore_vms):
+ """ Validate if a wildcard is used for ignored VMs. """
+ if '*' in ignore_vms:
+ return True
+
+
+def __check_vm_name_wildcard_pattern(vm_name, ignore_vms_list):
+ """ Validate if the VM name is in the ignore list pattern included. """
+ for ignore_vm in ignore_vms_list:
+ if '*' in ignore_vm:
+ if ignore_vm[:-1] in vm_name:
+ return True
+
+
+def __get_vm_tags(api_object, node, vmid):
+ """ Get a comment for a VM from a given VMID. """
+ info_prefix = 'Info: [api-get-vm-tags]:'
+
+ vm_config = api_object.nodes(node['node']).qemu(vmid).config.get()
+ logging.info(f'{info_prefix} Got VM comment from API.')
+ return vm_config.get('tags', None)
+
+
+def __get_proxlb_groups(vm_tags):
+ """ Get ProxLB related include and exclude groups. """
+ info_prefix = 'Info: [api-get-vm-include-exclude-tags]:'
+ group_include = None
+ group_exclude = None
+ vm_ignore = None
+
+ group_list = re.split(";", vm_tags)
+ for group in group_list:
+
+ if group.startswith('plb_include_'):
+ logging.info(f'{info_prefix} Got PLB include group.')
+ group_include = group
+
+ if group.startswith('plb_exclude_'):
+ logging.info(f'{info_prefix} Got PLB include group.')
+ group_exclude = group
+
+ if group.startswith('plb_ignore_vm'):
+ logging.info(f'{info_prefix} Got PLB ignore group.')
+ vm_ignore = True
+
+ return group_include, group_exclude, vm_ignore
+
+
def balancing_calculations(balancing_method, node_statistics, vm_statistics):
""" Calculate re-balancing of VMs on present nodes across the cluster. """
- error_prefix = 'Error: [rebalancing-calculator]:'
- info_prefix = 'Info: [rebalancing-calculator]:'
+ info_prefix = 'Info: [rebalancing-calculator]:'
+ balanciness = 10
+ rebalance = False
+ processed_vms = []
+ rebalance = True
+ emergency_counter = 0
- if balancing_method not in ['memory', 'disk', 'cpu']:
- logging.error(f'{error_prefix} Invalid balancing method: {balancing_method}')
- sys.exit(2)
- return node_statistics, vm_statistics
+ # Validate for a supported balancing method.
+ __validate_balancing_method(balancing_method)
- sorted_vms = sorted(vm_statistics.items(), key=lambda item: item[1][f'{balancing_method}_used'], reverse=True)
- logging.info(f'{info_prefix} Balancing will be done for {balancing_method} efficiency.')
+ # Rebalance VMs with the highest resource usage to a new
+ # node until reaching the desired balanciness.
+ while rebalance and emergency_counter < 10000:
+ emergency_counter = emergency_counter + 1
+ rebalance = __validate_balanciness(balanciness, balancing_method, node_statistics)
- total_resource_free = sum(node_info[f'{balancing_method}_free'] for node_info in node_statistics.values())
- total_resource_used = sum(vm_info[f'{balancing_method}_used'] for vm_info in vm_statistics.values())
+ if rebalance:
+ resource_highest_used_resources_vm, processed_vms = __get_most_used_resources_vm(balancing_method, vm_statistics, processed_vms)
+ resource_highest_free_resources_node = __get_most_free_resources_node(balancing_method, node_statistics)
+ node_statistics, vm_statistics = __update_resource_statistics(resource_highest_used_resources_vm, resource_highest_free_resources_node,
+ vm_statistics, node_statistics, balancing_method)
- if total_resource_used > total_resource_free:
- logging.error(f'{error_prefix} Not enough {balancing_method} resources to accommodate all VMs.')
- return node_statistics, vm_statistics
+ # Honour groupings for include and exclude groups for rebalancing VMs.
+ node_statistics, vm_statistics = __get_vm_tags_include_groups(vm_statistics, node_statistics, balancing_method)
+ node_statistics, vm_statistics = __get_vm_tags_exclude_groups(vm_statistics, node_statistics, balancing_method)
- # Rebalance in Round-robin initial distribution to ensure each node gets at least one VM.
- nodes = list(node_statistics.items())
- node_count = len(nodes)
- node_index = 0
-
- for vm_name, vm_info in sorted_vms:
- assigned = False
- for _ in range(node_count):
- node_name, node_info = nodes[node_index]
- if vm_info[f'{balancing_method}_used'] <= node_info[f'{balancing_method}_free']:
- vm_info['node_rebalance'] = node_name
- node_info[f'{balancing_method}_free'] -= vm_info[f'{balancing_method}_used']
- assigned = True
- node_index = (node_index + 1) % node_count
- break
- node_index = (node_index + 1) % node_count
-
- if not assigned:
- logging.error(f'{error_prefix} VM {vm_name} with {balancing_method} usage {vm_info[f"{balancing_method}_used"]} cannot fit into any node.')
-
- # Calculate and rebalance remaining VMs using best-fit strategy.
- while True:
- unassigned_vms = [vm for vm in vm_statistics.items() if 'node_rebalance' not in vm[1]]
- if not unassigned_vms:
- break
-
- for vm_name, vm_info in unassigned_vms:
- best_node_name = None
- best_node_info = None
- min_resource_diff = float('inf')
-
- for node_name, node_info in node_statistics.items():
- resource_free = node_info[f'{balancing_method}_free']
- resource_diff = resource_free - vm_info[f'{balancing_method}_used']
-
- if resource_diff >= 0 and resource_diff < min_resource_diff:
- min_resource_diff = resource_diff
- best_node_name = node_name
- best_node_info = node_info
-
- if best_node_name is not None:
- vm_info['node_rebalance'] = best_node_name
- best_node_info[f'{balancing_method}_free'] -= vm_info[f'{balancing_method}_used']
- else:
- logging.error(f'{error_prefix} VM {vm_name} with {balancing_method} usage {vm_info[f"{balancing_method}_used"]} cannot fit into any node.')
-
- # Remove VMs where 'node_rebalance' is the same as 'node_parent' since they
- # do not need to be migrated.
+ # Remove VMs that are not being relocated.
vms_to_remove = [vm_name for vm_name, vm_info in vm_statistics.items() if 'node_rebalance' in vm_info and vm_info['node_rebalance'] == vm_info.get('node_parent')]
for vm_name in vms_to_remove:
del vm_statistics[vm_name]
@@ -346,7 +383,55 @@ def balancing_calculations(balancing_method, node_statistics, vm_statistics):
return node_statistics, vm_statistics
-def __get_node_most_free_values(balancing_method, node_statistics):
+def __validate_balancing_method(balancing_method):
+ """ Validate for valid and supported balancing method. """
+ error_prefix = 'Error: [balancing-method-validation]:'
+ info_prefix = 'Info: [balancing-method-validation]]:'
+
+ if balancing_method not in ['memory', 'disk', 'cpu']:
+ logging.error(f'{error_prefix} Invalid balancing method: {balancing_method}')
+ sys.exit(2)
+ else:
+ logging.info(f'{info_prefix} Valid balancing method: {balancing_method}')
+
+
+def __validate_balanciness(balanciness, balancing_method, node_statistics):
+ """ Validate for balanciness to ensure further rebalancing is needed. """
+ info_prefix = 'Info: [balanciness-validation]]:'
+ node_memory_free_percent_list = []
+
+ for node_name, node_info in node_statistics.items():
+ node_memory_free_percent_list.append(node_info[f'{balancing_method}_free_percent'])
+
+ node_memory_free_percent_list_sorted = sorted(node_memory_free_percent_list)
+ node_lowest_percent = node_memory_free_percent_list_sorted[0]
+ node_highest_percent = node_memory_free_percent_list_sorted[-1]
+
+ if (node_lowest_percent + balanciness) < node_highest_percent:
+ logging.info(f'{info_prefix} Rebalancing is for {balancing_method} is needed.')
+ return True
+ else:
+ logging.info(f'{info_prefix} Rebalancing is for {balancing_method} is not needed.')
+ return False
+
+
+def __get_most_used_resources_vm(balancing_method, vm_statistics, processed_vms):
+ """ Get and return the most used resources of a VM by the defined balancing method. """
+ if balancing_method == 'memory':
+ vm = max(vm_statistics.items(), key=lambda item: item[1]['memory_used'] if item[0] not in processed_vms else -float('inf'))
+ processed_vms.append(vm[0])
+ return vm, processed_vms
+ if balancing_method == 'disk':
+ vm = max(vm_statistics.items(), key=lambda item: item[1]['disk_used'] if item[0] not in processed_vms else -float('inf'))
+ processed_vms.append(vm[0])
+ return vm, processed_vms
+ if balancing_method == 'cpu':
+ vm = max(vm_statistics.items(), key=lambda item: item[1]['cpu_used'] if item[0] not in processed_vms else -float('inf'))
+ processed_vms.append(vm[0])
+ return vm, processed_vms
+
+
+def __get_most_free_resources_node(balancing_method, node_statistics):
""" Get and return the most free resources of a node by the defined balancing method. """
if balancing_method == 'memory':
return max(node_statistics.items(), key=lambda item: item[1]['memory_free'])
@@ -356,6 +441,111 @@ def __get_node_most_free_values(balancing_method, node_statistics):
return max(node_statistics.items(), key=lambda item: item[1]['cpu_free'])
+def __update_resource_statistics(resource_highest_used_resources_vm, resource_highest_free_resources_node, vm_statistics, node_statistics, balancing_method):
+ """ Update VM and node resource statistics. """
+ info_prefix = 'Info: [rebalancing-resource-statistics-update]:'
+
+ if resource_highest_used_resources_vm[1]['node_parent'] != resource_highest_free_resources_node[0]:
+ vm_name = resource_highest_used_resources_vm[0]
+ vm_node_parent = resource_highest_used_resources_vm[1]['node_parent']
+ vm_node_rebalance = resource_highest_free_resources_node[0]
+ vm_resource_used = vm_statistics[resource_highest_used_resources_vm[0]][f'{balancing_method}_used']
+
+ # Update dictionaries for new values
+ # Assign new rebalance node to vm
+ vm_statistics[vm_name]['node_rebalance'] = vm_node_rebalance
+
+ # Recalculate values for nodes
+ ## Add freed resources to old parent node
+ node_statistics[vm_node_parent][f'{balancing_method}_used'] = int(node_statistics[vm_node_parent][f'{balancing_method}_used']) - int(vm_resource_used)
+ node_statistics[vm_node_parent][f'{balancing_method}_free'] = int(node_statistics[vm_node_parent][f'{balancing_method}_free']) + int(vm_resource_used)
+ node_statistics[vm_node_parent][f'{balancing_method}_free_percent'] = int(int(node_statistics[vm_node_parent][f'{balancing_method}_free']) / int(node_statistics[vm_node_parent][f'{balancing_method}_total']) * 100)
+
+ ## Removed newly allocated resources to new rebalanced node
+ node_statistics[vm_node_rebalance][f'{balancing_method}_used'] = int(node_statistics[vm_node_rebalance][f'{balancing_method}_used']) + int(vm_resource_used)
+ node_statistics[vm_node_rebalance][f'{balancing_method}_free'] = int(node_statistics[vm_node_rebalance][f'{balancing_method}_free']) - int(vm_resource_used)
+ node_statistics[vm_node_rebalance][f'{balancing_method}_free_percent'] = int(int(node_statistics[vm_node_rebalance][f'{balancing_method}_free']) / int(node_statistics[vm_node_rebalance][f'{balancing_method}_total']) * 100)
+
+ logging.info(f'{info_prefix} Updated VM and node statistics.')
+ return node_statistics, vm_statistics
+
+
+def __get_vm_tags_include_groups(vm_statistics, node_statistics, balancing_method):
+ """ Get VMs tags for include groups. """
+ info_prefix = 'Info: [rebalancing-tags-group-include]:'
+ tags_include_vms = {}
+ processed_vm = []
+
+ # Create groups of tags with belongings hosts.
+ for vm_name, vm_values in vm_statistics.items():
+ if vm_values.get('group_include', None):
+ if not tags_include_vms.get(vm_values['group_include'], None):
+ tags_include_vms[vm_values['group_include']] = [vm_name]
+ else:
+ tags_include_vms[vm_values['group_include']] = tags_include_vms[vm_values['group_include']] + [vm_name]
+
+ # Update the VMs to the corresponding node to their group assignments.
+ for group, vm_names in tags_include_vms.items():
+ # Do not take care of tags that have only a single host included.
+ if len(vm_names) < 2:
+ logging.info(f'{info_prefix} Only one host in group assignment.')
+ return node_statistics, vm_statistics
+
+ vm_node_rebalance = False
+ logging.info(f'{info_prefix} Create include groups of VM hosts.')
+ for vm_name in vm_names:
+ if vm_name not in processed_vm:
+ if not vm_node_rebalance:
+ vm_node_rebalance = vm_statistics[vm_name]['node_rebalance']
+ else:
+ _mocked_vm_object = (vm_name, vm_statistics[vm_name])
+ node_statistics, vm_statistics = __update_resource_statistics(_mocked_vm_object, [vm_node_rebalance],
+ vm_statistics, node_statistics, balancing_method)
+ processed_vm.append(vm_name)
+
+ return node_statistics, vm_statistics
+
+
+def __get_vm_tags_exclude_groups(vm_statistics, node_statistics, balancing_method):
+ """ Get VMs tags for exclude groups. """
+ info_prefix = 'Info: [rebalancing-tags-group-exclude]:'
+ tags_exclude_vms = {}
+ processed_vm = []
+
+ # Create groups of tags with belongings hosts.
+ for vm_name, vm_values in vm_statistics.items():
+ if vm_values.get('group_include', None):
+ if not tags_exclude_vms.get(vm_values['group_include'], None):
+ tags_exclude_vms[vm_values['group_include']] = [vm_name]
+ else:
+ tags_exclude_vms[vm_values['group_include']] = tags_exclude_vms[vm_values['group_include']] + [vm_name]
+
+ # Update the VMs to the corresponding node to their group assignments.
+ for group, vm_names in tags_exclude_vms.items():
+ # Do not take care of tags that have only a single host included.
+ if len(vm_names) < 2:
+ logging.info(f'{info_prefix} Only one host in group assignment.')
+ return node_statistics, vm_statistics
+
+ vm_node_rebalance = False
+ logging.info(f'{info_prefix} Create exclude groups of VM hosts.')
+ for vm_name in vm_names:
+ if vm_name not in processed_vm:
+ if not vm_node_rebalance:
+ random_node = vm_statistics[vm_name]['node_parent']
+ # Get a random node and make sure that it is not by accident the
+ # currently assigned one.
+ while random_node == vm_statistics[vm_name]['node_parent']:
+ random_node = random.choice(list(node_statistics.keys()))
+ else:
+ _mocked_vm_object = (vm_name, vm_statistics[vm_name])
+ node_statistics, vm_statistics = __update_resource_statistics(_mocked_vm_object, [random_node],
+ vm_statistics, node_statistics, balancing_method)
+ processed_vm.append(vm_name)
+
+ return node_statistics, vm_statistics
+
+
def run_vm_rebalancing(api_object, vm_statistics_rebalanced):
""" Run rebalancing of vms to new nodes in cluster. """
error_prefix = 'Error: [rebalancing-executor]:'
In Proxmox, you can ensure that certain VMs are ignored during the rebalancing process by setting a specific tag within the Proxmox Web UI, rather than solely relying on configurations in the ProxLB config file. This can be achieved by adding the tag 'plb_ignore_vm' to the VM. Once this tag is applied, the VM will be excluded from any further rebalancing operations, simplifying the management process.
+
### Systemd
When installing a Linux distribution (such as .deb or .rpm) file, this will be shipped with a systemd unit file. The default configuration file will be sourced from `/etc/proxlb/proxlb.conf`.
diff --git a/docs/02_Configuration.md b/docs/02_Configuration.md
index e69de29..47374b0 100644
--- a/docs/02_Configuration.md
+++ b/docs/02_Configuration.md
@@ -0,0 +1,10 @@
+# Configuration
+## Grouping
+### Include (Stay Together)
+ Access the Proxmox Web UI by opening your web browser and navigating to your Proxmox VE web interface, then log in with your credentials. Navigate to the VM you want to tag by selecting it from the left-hand navigation panel. Click on the "Options" tab to view the VM's options, then select "Edit" or "Add" (depending on whether you are editing an existing tag or adding a new one). In the tag field, enter plb_include_ followed by your unique identifier, for example, plb_include_group1. Save the changes to apply the tag to the VM. Repeat these steps for each VM that should be included in the group.
+
+### Exclude (Stay Separate)
+ Access the Proxmox Web UI by opening your web browser and navigating to your Proxmox VE web interface, then log in with your credentials. Navigate to the VM you want to tag by selecting it from the left-hand navigation panel. Click on the "Options" tab to view the VM's options, then select "Edit" or "Add" (depending on whether you are editing an existing tag or adding a new one). In the tag field, enter plb_exclude_ followed by your unique identifier, for example, plb_exclude_critical. Save the changes to apply the tag to the VM. Repeat these steps for each VM that should be excluded from being on the same node.
+
+### Ignore VMs (tag style)
+ In Proxmox, you can ensure that certain VMs are ignored during the rebalancing process by setting a specific tag within the Proxmox Web UI, rather than solely relying on configurations in the ProxLB config file. This can be achieved by adding the tag 'plb_ignore_vm' to the VM. Once this tag is applied, the VM will be excluded from any further rebalancing operations, simplifying the management process.
\ No newline at end of file
diff --git a/proxlb b/proxlb
index 236dba6..3509e76 100755
--- a/proxlb
+++ b/proxlb
@@ -29,6 +29,8 @@ try:
_imports = True
except ImportError as error:
_imports = False
+import random
+import re
import requests
import sys
import time
@@ -226,15 +228,18 @@ def get_node_statistics(api_object, ignore_nodes):
for node in api_object.nodes.get():
if node['status'] == 'online' and node['node'] not in ignore_nodes_list:
node_statistics[node['node']] = {}
- node_statistics[node['node']]['cpu_total'] = node['maxcpu']
- node_statistics[node['node']]['cpu_used'] = node['cpu']
- node_statistics[node['node']]['cpu_free'] = int(node['maxcpu']) - int(node['cpu'])
- node_statistics[node['node']]['memory_total'] = node['maxmem']
- node_statistics[node['node']]['memory_used'] = node['mem']
- node_statistics[node['node']]['memory_free'] = int(node['maxmem']) - int(node['mem'])
- node_statistics[node['node']]['disk_total'] = node['maxdisk']
- node_statistics[node['node']]['disk_used'] = node['disk']
- node_statistics[node['node']]['disk_free'] = int(node['maxdisk']) - int(node['disk'])
+ node_statistics[node['node']]['cpu_total'] = node['maxcpu']
+ node_statistics[node['node']]['cpu_used'] = node['cpu']
+ node_statistics[node['node']]['cpu_free'] = int(node['maxcpu']) - int(node['cpu'])
+ node_statistics[node['node']]['cpu_free_percent'] = int((node_statistics[node['node']]['cpu_free']) / int(node['maxcpu']) * 100)
+ node_statistics[node['node']]['memory_total'] = node['maxmem']
+ node_statistics[node['node']]['memory_used'] = node['mem']
+ node_statistics[node['node']]['memory_free'] = int(node['maxmem']) - int(node['mem'])
+ node_statistics[node['node']]['memory_free_percent'] = int((node_statistics[node['node']]['memory_free']) / int(node['maxmem']) * 100)
+ node_statistics[node['node']]['disk_total'] = node['maxdisk']
+ node_statistics[node['node']]['disk_used'] = node['disk']
+ node_statistics[node['node']]['disk_free'] = int(node['maxdisk']) - int(node['disk'])
+ node_statistics[node['node']]['disk_free_percent'] = int((node_statistics[node['node']]['disk_free']) / int(node['maxdisk']) * 100)
logging.info(f'{info_prefix} Added node {node["node"]}.')
logging.info(f'{info_prefix} Created node statistics.')
@@ -243,15 +248,38 @@ def get_node_statistics(api_object, ignore_nodes):
def get_vm_statistics(api_object, ignore_vms):
""" Get statistics of cpu, memory and disk for each vm in the cluster. """
- info_prefix = 'Info: [vm-statistics]:'
- vm_statistics = {}
- ignore_vms_list = ignore_vms.split(',')
+ info_prefix = 'Info: [vm-statistics]:'
+ vm_statistics = {}
+ ignore_vms_list = ignore_vms.split(',')
+ group_include = None
+ group_exclude = None
+ vm_ignore = None
+ vm_ignore_wildcard = False
+
+ # Wildcard support: Initially validate if we need to honour
+ # any wildcards within the vm_ignore list.
+ vm_ignore_wildcard = __validate_ignore_vm_wildcard(ignore_vms)
for node in api_object.nodes.get():
for vm in api_object.nodes(node['node']).qemu.get():
- if vm['status'] == 'running' and vm['name'] not in ignore_vms_list:
+ # Get the VM tags from API.
+ vm_tags = __get_vm_tags(api_object, node, vm['vmid'])
+ if vm_tags is not None:
+ group_include, group_exclude, vm_ignore = __get_proxlb_groups(vm_tags)
+
+ # Get wildcard match for VMs to ignore if a wildcard pattern was
+ # previously found. Wildcards may slow down the task when using
+ # many patterns in the ignore list. Therefore, run this only if
+ # a wildcard pattern was found. We also do not need to validate
+ # this if the VM is already being ignored by a defined tag.
+ if vm_ignore_wildcard and not vm_ignore:
+ vm_ignore = __check_vm_name_wildcard_pattern(vm['name'], ignore_vms_list)
+
+ if vm['status'] == 'running' and vm['name'] not in ignore_vms_list and not vm_ignore:
vm_statistics[vm['name']] = {}
+ vm_statistics[vm['name']]['group_include'] = group_include
+ vm_statistics[vm['name']]['group_exclude'] = group_exclude
vm_statistics[vm['name']]['cpu_total'] = vm['cpus']
vm_statistics[vm['name']]['cpu_used'] = vm['cpu']
vm_statistics[vm['name']]['memory_total'] = vm['maxmem']
@@ -270,74 +298,83 @@ def get_vm_statistics(api_object, ignore_vms):
return vm_statistics
+def __validate_ignore_vm_wildcard(ignore_vms):
+ """ Validate if a wildcard is used for ignored VMs. """
+ if '*' in ignore_vms:
+ return True
+
+
+def __check_vm_name_wildcard_pattern(vm_name, ignore_vms_list):
+ """ Validate if the VM name is in the ignore list pattern included. """
+ for ignore_vm in ignore_vms_list:
+ if '*' in ignore_vm:
+ if ignore_vm[:-1] in vm_name:
+ return True
+
+
+def __get_vm_tags(api_object, node, vmid):
+ """ Get a comment for a VM from a given VMID. """
+ info_prefix = 'Info: [api-get-vm-tags]:'
+
+ vm_config = api_object.nodes(node['node']).qemu(vmid).config.get()
+ logging.info(f'{info_prefix} Got VM comment from API.')
+ return vm_config.get('tags', None)
+
+
+def __get_proxlb_groups(vm_tags):
+ """ Get ProxLB related include and exclude groups. """
+ info_prefix = 'Info: [api-get-vm-include-exclude-tags]:'
+ group_include = None
+ group_exclude = None
+ vm_ignore = None
+
+ group_list = re.split(";", vm_tags)
+ for group in group_list:
+
+ if group.startswith('plb_include_'):
+ logging.info(f'{info_prefix} Got PLB include group.')
+ group_include = group
+
+ if group.startswith('plb_exclude_'):
+ logging.info(f'{info_prefix} Got PLB include group.')
+ group_exclude = group
+
+ if group.startswith('plb_ignore_vm'):
+ logging.info(f'{info_prefix} Got PLB ignore group.')
+ vm_ignore = True
+
+ return group_include, group_exclude, vm_ignore
+
+
def balancing_calculations(balancing_method, node_statistics, vm_statistics):
""" Calculate re-balancing of VMs on present nodes across the cluster. """
- error_prefix = 'Error: [rebalancing-calculator]:'
- info_prefix = 'Info: [rebalancing-calculator]:'
+ info_prefix = 'Info: [rebalancing-calculator]:'
+ balanciness = 10
+ rebalance = False
+ processed_vms = []
+ rebalance = True
+ emergency_counter = 0
- if balancing_method not in ['memory', 'disk', 'cpu']:
- logging.error(f'{error_prefix} Invalid balancing method: {balancing_method}')
- sys.exit(2)
- return node_statistics, vm_statistics
+ # Validate for a supported balancing method.
+ __validate_balancing_method(balancing_method)
- sorted_vms = sorted(vm_statistics.items(), key=lambda item: item[1][f'{balancing_method}_used'], reverse=True)
- logging.info(f'{info_prefix} Balancing will be done for {balancing_method} efficiency.')
+ # Rebalance VMs with the highest resource usage to a new
+ # node until reaching the desired balanciness.
+ while rebalance and emergency_counter < 10000:
+ emergency_counter = emergency_counter + 1
+ rebalance = __validate_balanciness(balanciness, balancing_method, node_statistics)
- total_resource_free = sum(node_info[f'{balancing_method}_free'] for node_info in node_statistics.values())
- total_resource_used = sum(vm_info[f'{balancing_method}_used'] for vm_info in vm_statistics.values())
+ if rebalance:
+ resource_highest_used_resources_vm, processed_vms = __get_most_used_resources_vm(balancing_method, vm_statistics, processed_vms)
+ resource_highest_free_resources_node = __get_most_free_resources_node(balancing_method, node_statistics)
+ node_statistics, vm_statistics = __update_resource_statistics(resource_highest_used_resources_vm, resource_highest_free_resources_node,
+ vm_statistics, node_statistics, balancing_method)
- if total_resource_used > total_resource_free:
- logging.error(f'{error_prefix} Not enough {balancing_method} resources to accommodate all VMs.')
- return node_statistics, vm_statistics
+ # Honour groupings for include and exclude groups for rebalancing VMs.
+ node_statistics, vm_statistics = __get_vm_tags_include_groups(vm_statistics, node_statistics, balancing_method)
+ node_statistics, vm_statistics = __get_vm_tags_exclude_groups(vm_statistics, node_statistics, balancing_method)
- # Rebalance in Round-robin initial distribution to ensure each node gets at least one VM.
- nodes = list(node_statistics.items())
- node_count = len(nodes)
- node_index = 0
-
- for vm_name, vm_info in sorted_vms:
- assigned = False
- for _ in range(node_count):
- node_name, node_info = nodes[node_index]
- if vm_info[f'{balancing_method}_used'] <= node_info[f'{balancing_method}_free']:
- vm_info['node_rebalance'] = node_name
- node_info[f'{balancing_method}_free'] -= vm_info[f'{balancing_method}_used']
- assigned = True
- node_index = (node_index + 1) % node_count
- break
- node_index = (node_index + 1) % node_count
-
- if not assigned:
- logging.error(f'{error_prefix} VM {vm_name} with {balancing_method} usage {vm_info[f"{balancing_method}_used"]} cannot fit into any node.')
-
- # Calculate and rebalance remaining VMs using best-fit strategy.
- while True:
- unassigned_vms = [vm for vm in vm_statistics.items() if 'node_rebalance' not in vm[1]]
- if not unassigned_vms:
- break
-
- for vm_name, vm_info in unassigned_vms:
- best_node_name = None
- best_node_info = None
- min_resource_diff = float('inf')
-
- for node_name, node_info in node_statistics.items():
- resource_free = node_info[f'{balancing_method}_free']
- resource_diff = resource_free - vm_info[f'{balancing_method}_used']
-
- if resource_diff >= 0 and resource_diff < min_resource_diff:
- min_resource_diff = resource_diff
- best_node_name = node_name
- best_node_info = node_info
-
- if best_node_name is not None:
- vm_info['node_rebalance'] = best_node_name
- best_node_info[f'{balancing_method}_free'] -= vm_info[f'{balancing_method}_used']
- else:
- logging.error(f'{error_prefix} VM {vm_name} with {balancing_method} usage {vm_info[f"{balancing_method}_used"]} cannot fit into any node.')
-
- # Remove VMs where 'node_rebalance' is the same as 'node_parent' since they
- # do not need to be migrated.
+ # Remove VMs that are not being relocated.
vms_to_remove = [vm_name for vm_name, vm_info in vm_statistics.items() if 'node_rebalance' in vm_info and vm_info['node_rebalance'] == vm_info.get('node_parent')]
for vm_name in vms_to_remove:
del vm_statistics[vm_name]
@@ -346,7 +383,55 @@ def balancing_calculations(balancing_method, node_statistics, vm_statistics):
return node_statistics, vm_statistics
-def __get_node_most_free_values(balancing_method, node_statistics):
+def __validate_balancing_method(balancing_method):
+ """ Validate for valid and supported balancing method. """
+ error_prefix = 'Error: [balancing-method-validation]:'
+ info_prefix = 'Info: [balancing-method-validation]]:'
+
+ if balancing_method not in ['memory', 'disk', 'cpu']:
+ logging.error(f'{error_prefix} Invalid balancing method: {balancing_method}')
+ sys.exit(2)
+ else:
+ logging.info(f'{info_prefix} Valid balancing method: {balancing_method}')
+
+
+def __validate_balanciness(balanciness, balancing_method, node_statistics):
+ """ Validate for balanciness to ensure further rebalancing is needed. """
+ info_prefix = 'Info: [balanciness-validation]]:'
+ node_memory_free_percent_list = []
+
+ for node_name, node_info in node_statistics.items():
+ node_memory_free_percent_list.append(node_info[f'{balancing_method}_free_percent'])
+
+ node_memory_free_percent_list_sorted = sorted(node_memory_free_percent_list)
+ node_lowest_percent = node_memory_free_percent_list_sorted[0]
+ node_highest_percent = node_memory_free_percent_list_sorted[-1]
+
+ if (node_lowest_percent + balanciness) < node_highest_percent:
+ logging.info(f'{info_prefix} Rebalancing is for {balancing_method} is needed.')
+ return True
+ else:
+ logging.info(f'{info_prefix} Rebalancing is for {balancing_method} is not needed.')
+ return False
+
+
+def __get_most_used_resources_vm(balancing_method, vm_statistics, processed_vms):
+ """ Get and return the most used resources of a VM by the defined balancing method. """
+ if balancing_method == 'memory':
+ vm = max(vm_statistics.items(), key=lambda item: item[1]['memory_used'] if item[0] not in processed_vms else -float('inf'))
+ processed_vms.append(vm[0])
+ return vm, processed_vms
+ if balancing_method == 'disk':
+ vm = max(vm_statistics.items(), key=lambda item: item[1]['disk_used'] if item[0] not in processed_vms else -float('inf'))
+ processed_vms.append(vm[0])
+ return vm, processed_vms
+ if balancing_method == 'cpu':
+ vm = max(vm_statistics.items(), key=lambda item: item[1]['cpu_used'] if item[0] not in processed_vms else -float('inf'))
+ processed_vms.append(vm[0])
+ return vm, processed_vms
+
+
+def __get_most_free_resources_node(balancing_method, node_statistics):
""" Get and return the most free resources of a node by the defined balancing method. """
if balancing_method == 'memory':
return max(node_statistics.items(), key=lambda item: item[1]['memory_free'])
@@ -356,6 +441,111 @@ def __get_node_most_free_values(balancing_method, node_statistics):
return max(node_statistics.items(), key=lambda item: item[1]['cpu_free'])
+def __update_resource_statistics(resource_highest_used_resources_vm, resource_highest_free_resources_node, vm_statistics, node_statistics, balancing_method):
+ """ Update VM and node resource statistics. """
+ info_prefix = 'Info: [rebalancing-resource-statistics-update]:'
+
+ if resource_highest_used_resources_vm[1]['node_parent'] != resource_highest_free_resources_node[0]:
+ vm_name = resource_highest_used_resources_vm[0]
+ vm_node_parent = resource_highest_used_resources_vm[1]['node_parent']
+ vm_node_rebalance = resource_highest_free_resources_node[0]
+ vm_resource_used = vm_statistics[resource_highest_used_resources_vm[0]][f'{balancing_method}_used']
+
+ # Update dictionaries for new values
+ # Assign new rebalance node to vm
+ vm_statistics[vm_name]['node_rebalance'] = vm_node_rebalance
+
+ # Recalculate values for nodes
+ ## Add freed resources to old parent node
+ node_statistics[vm_node_parent][f'{balancing_method}_used'] = int(node_statistics[vm_node_parent][f'{balancing_method}_used']) - int(vm_resource_used)
+ node_statistics[vm_node_parent][f'{balancing_method}_free'] = int(node_statistics[vm_node_parent][f'{balancing_method}_free']) + int(vm_resource_used)
+ node_statistics[vm_node_parent][f'{balancing_method}_free_percent'] = int(int(node_statistics[vm_node_parent][f'{balancing_method}_free']) / int(node_statistics[vm_node_parent][f'{balancing_method}_total']) * 100)
+
+ ## Removed newly allocated resources to new rebalanced node
+ node_statistics[vm_node_rebalance][f'{balancing_method}_used'] = int(node_statistics[vm_node_rebalance][f'{balancing_method}_used']) + int(vm_resource_used)
+ node_statistics[vm_node_rebalance][f'{balancing_method}_free'] = int(node_statistics[vm_node_rebalance][f'{balancing_method}_free']) - int(vm_resource_used)
+ node_statistics[vm_node_rebalance][f'{balancing_method}_free_percent'] = int(int(node_statistics[vm_node_rebalance][f'{balancing_method}_free']) / int(node_statistics[vm_node_rebalance][f'{balancing_method}_total']) * 100)
+
+ logging.info(f'{info_prefix} Updated VM and node statistics.')
+ return node_statistics, vm_statistics
+
+
+def __get_vm_tags_include_groups(vm_statistics, node_statistics, balancing_method):
+ """ Get VMs tags for include groups. """
+ info_prefix = 'Info: [rebalancing-tags-group-include]:'
+ tags_include_vms = {}
+ processed_vm = []
+
+ # Create groups of tags with belongings hosts.
+ for vm_name, vm_values in vm_statistics.items():
+ if vm_values.get('group_include', None):
+ if not tags_include_vms.get(vm_values['group_include'], None):
+ tags_include_vms[vm_values['group_include']] = [vm_name]
+ else:
+ tags_include_vms[vm_values['group_include']] = tags_include_vms[vm_values['group_include']] + [vm_name]
+
+ # Update the VMs to the corresponding node to their group assignments.
+ for group, vm_names in tags_include_vms.items():
+ # Do not take care of tags that have only a single host included.
+ if len(vm_names) < 2:
+ logging.info(f'{info_prefix} Only one host in group assignment.')
+ return node_statistics, vm_statistics
+
+ vm_node_rebalance = False
+ logging.info(f'{info_prefix} Create include groups of VM hosts.')
+ for vm_name in vm_names:
+ if vm_name not in processed_vm:
+ if not vm_node_rebalance:
+ vm_node_rebalance = vm_statistics[vm_name]['node_rebalance']
+ else:
+ _mocked_vm_object = (vm_name, vm_statistics[vm_name])
+ node_statistics, vm_statistics = __update_resource_statistics(_mocked_vm_object, [vm_node_rebalance],
+ vm_statistics, node_statistics, balancing_method)
+ processed_vm.append(vm_name)
+
+ return node_statistics, vm_statistics
+
+
+def __get_vm_tags_exclude_groups(vm_statistics, node_statistics, balancing_method):
+ """ Get VMs tags for exclude groups. """
+ info_prefix = 'Info: [rebalancing-tags-group-exclude]:'
+ tags_exclude_vms = {}
+ processed_vm = []
+
+ # Create groups of tags with belongings hosts.
+ for vm_name, vm_values in vm_statistics.items():
+ if vm_values.get('group_include', None):
+ if not tags_exclude_vms.get(vm_values['group_include'], None):
+ tags_exclude_vms[vm_values['group_include']] = [vm_name]
+ else:
+ tags_exclude_vms[vm_values['group_include']] = tags_exclude_vms[vm_values['group_include']] + [vm_name]
+
+ # Update the VMs to the corresponding node to their group assignments.
+ for group, vm_names in tags_exclude_vms.items():
+ # Do not take care of tags that have only a single host included.
+ if len(vm_names) < 2:
+ logging.info(f'{info_prefix} Only one host in group assignment.')
+ return node_statistics, vm_statistics
+
+ vm_node_rebalance = False
+ logging.info(f'{info_prefix} Create exclude groups of VM hosts.')
+ for vm_name in vm_names:
+ if vm_name not in processed_vm:
+ if not vm_node_rebalance:
+ random_node = vm_statistics[vm_name]['node_parent']
+ # Get a random node and make sure that it is not by accident the
+ # currently assigned one.
+ while random_node == vm_statistics[vm_name]['node_parent']:
+ random_node = random.choice(list(node_statistics.keys()))
+ else:
+ _mocked_vm_object = (vm_name, vm_statistics[vm_name])
+ node_statistics, vm_statistics = __update_resource_statistics(_mocked_vm_object, [random_node],
+ vm_statistics, node_statistics, balancing_method)
+ processed_vm.append(vm_name)
+
+ return node_statistics, vm_statistics
+
+
def run_vm_rebalancing(api_object, vm_statistics_rebalanced):
""" Run rebalancing of vms to new nodes in cluster. """
error_prefix = 'Error: [rebalancing-executor]:'